先日、ネコの慢性腎臓病(CKD)に対して「子宮由来メセンキムストローマ細胞(UMSC)」を投与する研究に関するPDFを入手しました。これは、Shelly ZachariasさんやLinda L. Blackさんらが進めてきた研究で、CKDのネコに点滴でMSCを投与したらどう変化が見られるのかを検証している内容です。
この論文は専門用語が多く、加えて投与量や対象猫の年齢などの具体的な数字が重要なポイントになっていました。従来の手動コピーペーストでは、論文の情報を丸ごと読み込ませるのは大変。そこで今回は、**RAG(Retrieval Augmented Generation)**の機能を使って、直接PDFを取り込む形でAIに学習させてみることにしました。
RAGの手順
- PDF対応の環境整備
- AI Power(WordPressプラグイン)の有料版など、PDFをアップロードしてEmbeddingsを作成できる環境を用意。
- Pinecone等のベクターデータベースを使い、論文のチャンクを自動生成して管理。
- AIに論文を“取り込み”
- PDFをアップロードし、自動的に数百~数千トークン程度のテキストに分割してEmbeddingsを作成。
- これでAIが論文内容を「検索しながら回答」できるようになる。
- 実験:学習させないと分からない質問をぶつける
- たとえば「この研究で使われた具体的な被験猫の数」「投与スケジュール」など、本文に記載されていないと答えにくい質問を出す。
- 回答精度のチェック
- RAGなし(単に記憶ベースのChatGPT等)では答えがあいまいになりがちな点を、RAGを用いたことでどこまで向上するかを比較した。
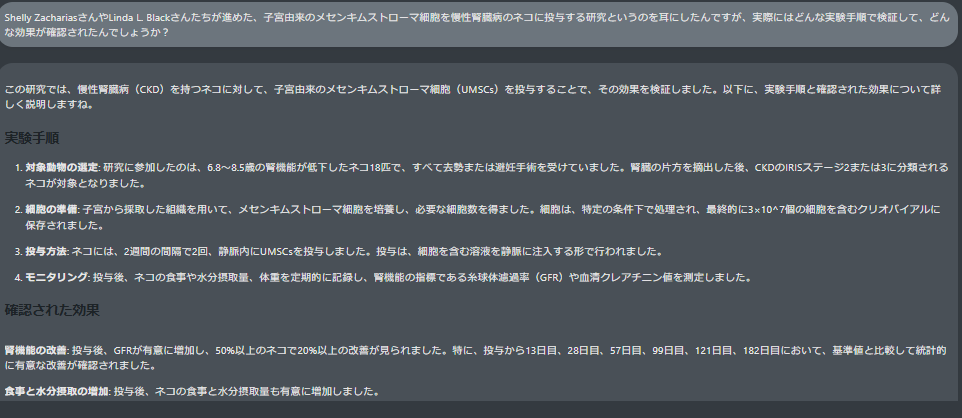
結果・所感
- 完全一致とはいかないまでも精度が向上
- 投与量や観察日などの具体的な数字を正しく回答してくれる頻度が、手動でコピーペーストしていた頃より増えた印象でした。
- ただし、引用内容が一部抜けていたり、統計結果が混同されたりするケースも。
- 論文中の専門的なパラメータを把握するうえで便利
- 数値が多い研究ほど、RAGのメリットを実感しやすいと感じました。
- PDFの構造や段組みによって抽出精度が左右される
- 上手くテキストを分割できない箇所や、表・図などは情報が抜け落ちる場合も。
- 今回は論文本文中心でしたが、表やグラフからのデータ抽出はまだ課題。
今回はPDF論文を直接RAGに取り込み、手動コピーペーストより効率よくAIに論文情報を参照させる実験を行いました。結果として、「まだ誤差はあるが、必要な数値情報などを以前より正確に返してくれるようになった」という手応えを感じています。学術分野のように専門用語や細かいデータが多い文書ほど、RAGの恩恵は大きいと予想されます。
今後は、表や図の取り込み精度を向上させたり、ファインチューニング用のデータ(Q&A形式のjsonlなど)を作ってモデルをカスタムすることで、さらに高い再現性を狙いたいと思います。興味のある方はぜひRAG対応のプラグインやサービスを試してみてください。